What is a star schema?
The primary characteristic of star schema is its use of dimension tables rather than single-attribute lookup tables. For example, a Time dimension in a star schema may be supported by a dimension table with the following structure:
DAY_ID | DAY_DESC | MONTH_ID | MONTH_DESC | QUARTER_ID | QUARTER_DESC | YEAR_ID |
|
|
|
|
|
|
|
By contrast, a snowflake schema has a separate lookup table for each level of a dimension. In a fully normalized snowflake schema, each lookup table contains only its attribute's ID and description columns, and the ID of its parent to facilitate joins up the hierarchy. Lookup tables may also be partially denormalized, in which ID columns of all parents in the dimension are included, or fully denormalized, in which IDs and descriptions of all parents are included.
Fully normalized snowflake schema:
DAY_ID | DAY_DESC | MONTH_ID |
|
|
|
MONTH_ID | MONTH_DESC | QUARTER_ID |
|
|
|
QUARTER_ID | QUARTER_DESC | YEAR_ID |
|
|
|
YEAR_ID |
|
Partially denormalized snowflake schema:
DAY_ID | DAY_DESC | MONTH_ID | QUARTER_ID | YEAR_ID |
|
|
|
|
|
MONTH_ID | MONTH_DESC | QUARTER_ID | YEAR_ID |
|
|
|
|
QUARTER_ID | QUARTER_DESC | YEAR_ID |
|
|
|
YEAR_ID |
|
Fully denormalized snowflake schema:
DAY_ID | DAY_DESC | MONTH_ID | MONTH_DESC | QUARTER_ID | QUARTER_DESC | YEAR_ID |
|
|
|
|
|
|
|
MONTH_ID | MONTH_DESC | QUARTER_ID | QUARTER_DESC | YEAR_ID |
|
|
|
|
|
QUARTER_ID | QUARTER_DESC | YEAR_ID |
|
|
|
YEAR_ID |
|
Star schemas and fully denormalized schemas minimize the number of table joins that must be performed in SQL queries. A lower number of joins generally translates into better query performance, at the cost of higher data redundancy.
MicroStrategy SQL Generation Engine can work with properly designed star schema warehouses, however there are restrictions. Not all functionality can be done with a star schema warehouse.
Star schemas and aggregate (or summary) fact tables
Aggregate tables can further improve query performance by reducing the number of rows over which higher-level metrics must be aggregated. Further information they be found in the following MicroStrategy Knowledgebase article.
KB9862: How do aggregate tables work MicroStrategy
However, the use of aggregate tables with dimension tables is not a valid physical modeling strategy. Whenever aggregation is performed over fact data, it is a general requirement that tables joined to the fact table must be at the same attribute level or at a higher level. If the auxiliary table is at a lower level, fact rows will be replicated prior to aggregation and this will result in inflated metric values (also known as "multiple counting").
With the above Time dimension table, a fact table at the level of Day functions correctly because there is exactly one row in DIM_TIME for each day. To aggregate the facts to the level of Quarter, it is valid to join the fact table to the dimension table and group by the quarter ID from the dimension table.
Sql
select DT.QUARTER_ID,
max(DT.QUARTER_DESC) Quarter_Desc
sum(FT.REVENUE) Revenue
from DAY_FACT_TABLE FT
join DIM_TIME DT
on (FT.DAY_ID = DT.DAY_ID)
group by DT.QUARTER_ID
If, however, there is an aggregate fact table already at the level of Quarter, the results will not be correct. This is because the query must join on Quarter ID, but the quarter ID is not a unique key of the dimension table. Because any given quarter of a year contains 90, 91 or 92 days, the dimension table will contain that many rows with the same quarter ID. Thus fact rows will be replicated prior to taking the sum, and the sum will be too high.
Sql
select FT.QUARTER_ID,
max(DT.QUARTER_DESC) Quarter_Desc
sum(FT.REVENUE) Revenue
from QTR_FACT_TABLE FT
join DIM_TIME DT
on (FT.QUARTER_ID = DT.QUARTER_ID)
group by FT.QUARTER_ID
This is a generally recognized problem with star schemas, and is not strictly a MicroStrategy limitation.
Star schemas will function correctly with MicroStrategy SQL Generation Engine 8.x as long as they obey the general data warehousing principle that fact tables should not be at a higher level than the dimension tables to which they are joined.
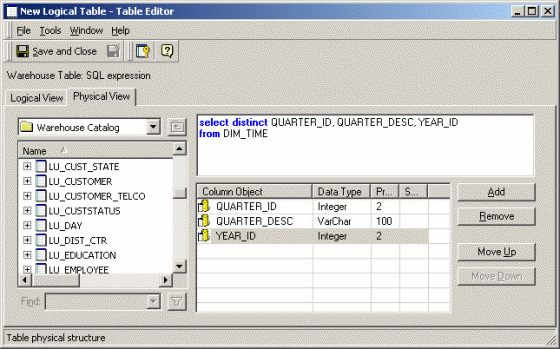
If aggregate tables are required, it is necessary to provide higher-level lookup tables with unique rows corresponding to each aggregate table's key. Logical views are a way to do this without adding tables or views to the warehouse. For example, LWV_LU_QUARTER may be defined using the following SQL statement:
Sql
select distinct QUARTER_ID, QUARTER_DESC, YEAR_ID
from DIM_TIME
With this logical view, it becomes possible for MicroStrategy SQL Generation Engine 8.x to query the quarter-level fact table as follows. Since the logical view has distinct rows per quarter, multiple counting will not occur in this query.
Sql
select FT.QUARTER_ID,
max(LQ.QUARTER_DESC) Quarter_Desc
sum(FT.REVENUE) Revenue
from QTR_FACT_TABLE FT
join (select distinct QUARTER_ID, QUARTER_DESC, YEAR_ID
from DIM_TIME) LQ
on (FT.QUARTER_ID = LQ.QUARTER_ID)
group by FT.QUARTER_ID
For more information on the use of logical views in MicroStrategy SQL Generation Engine 8.1.x and 9.x, consult the MicroStrategy Project Design Guide manual, Appendix B: Logical Tables, "Creating logical tables."
KB19194