SUMMARY
This document provides guidelines to efficiently use Strategy 10 Secure Enterprise Platform PRIME partitioning as well as provide awareness of the limitations it has.
What is Strategy PRIME?
Strategy PRIME is a new feature added in Strategy 10 Secure Enterprise Platform, which represents the evolution of the OLAP Intelligent Cubes. Its name stands for Strategy Parallel Relational In-Memory Engine.
Strategy PRIME uses Strategy Web Data Import Tool to build In-Memory Cubes that will be used by the PRIME Engine to fulfill data requests. One of the most interesting features of this In-Memory Cubes is the capacity to handle partitioning.
For additional information information on Strategy Prime, refer to the following Strategy Knowledge Base Document:
KB221530: Strategy PRIME overview for Strategy 10 Secure Enterprise Platform
What is partitioning?
Partitioning is the act of distributing data across multiple cores on a single box and/or distributing data across nodes in a Massively Parallel Processing Cluster to enable parallel processing of information.
On the single node edition of PRIME, this is accomplished by harnessing the power of all CPU cores. Each data partition is in a “shared nothing” architecture and will only work with only its own corresponding CPU core or cores.
Note: This does not refer to an Intelligence server cluster. It is not possible to partition a cube on multiple nodes of an Intelligence server.
How is partitioning accessed ?
Once some tables or files have been imported in the Strategy Data Import Tool, access to the "All Objects Vew".
Once in the All objects view, the partitioning attribute (or Distribution Key) can be selected, and also, the number of partitions (or Distributions) can be defined.
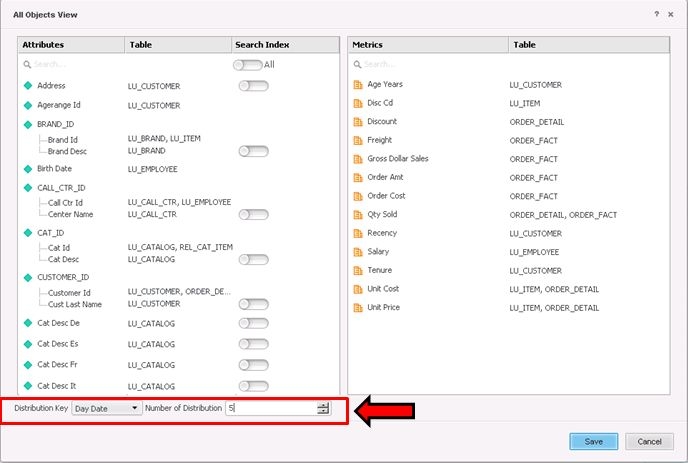
For more information on partitioning, see How to Partition Large Datasets and Create Search Indexes.
Important considerations:
Picking a partition attribute and number of partitions: