INTRODUCTION
The Strategy Enterprise Platform 10.x is now certified on Apache Spark, the in-memory processing engine that is part of all major Hadoop distributions. This integration leverages the power of the Strategy Enterprise Platform to run analytics against Hadoop and Big Data stores. Apache Spark is supported as a warehouse only which can be used through Data Import in Web (as a DSN connection or DSN-less connection) and as a warehouse through Strategy Developer.
Starting in Strategy 2019, Hive is not available via the Connectivity Wizard. For Strategy versions 2019 and later, you must create a DSN by editing ODBC.ini or use ODBC Data Sources (x64) using the Strategy Spark ODBC Driver that is shipped out-of-the-box.
PREREQUISITES
1. A supported version of Apache Spark SQL
2. A DSN with the Strategy ODBC driver for Apache Hive Wire Protocol
Note: A DSN is not needed for the DSN-less option in Data Import.
STEPS TO CONNECT TO APACHE SPARK
Connecting to Apache Spark as a warehouse
Through the ODBC Administrator:
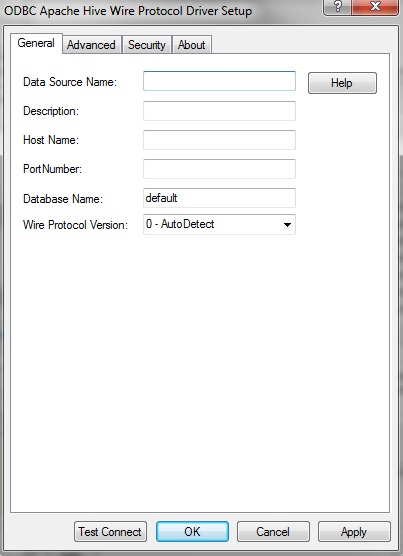
Through Connectivity Wizard:
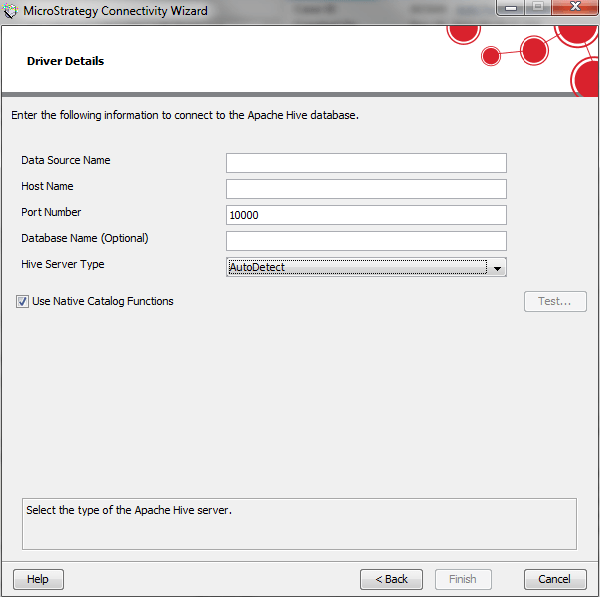
Note: Test the connectivity to ensure the connection is established.
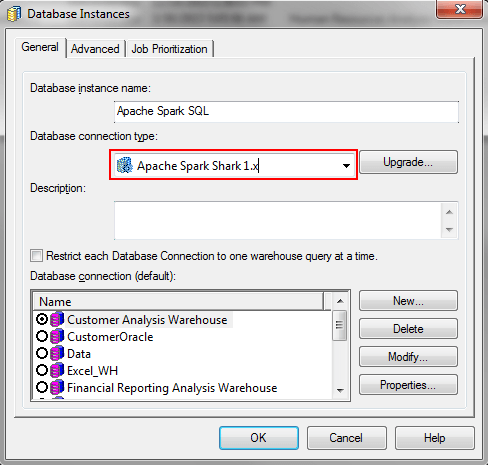
Now users can pull tables into their Projects through Warehouse Catalog or Strategy Architect using this Database Instance.
Connecting to Apache Spark through Data Import with a DSN
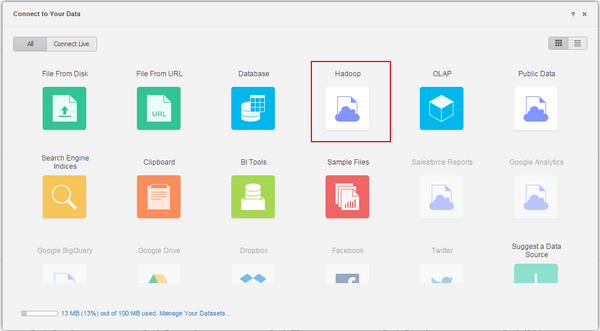
Note: ‘Browse Hadoop Files using Strategy Big Data Engine’ is only for connecting to the Hadoop Gateway (Big Data Engine).
Note: Users can save the Data Import cube as a Live Connection or an In-Memory dataset.
Connecting to Apache Spark through Data Import with a DSN-less connection
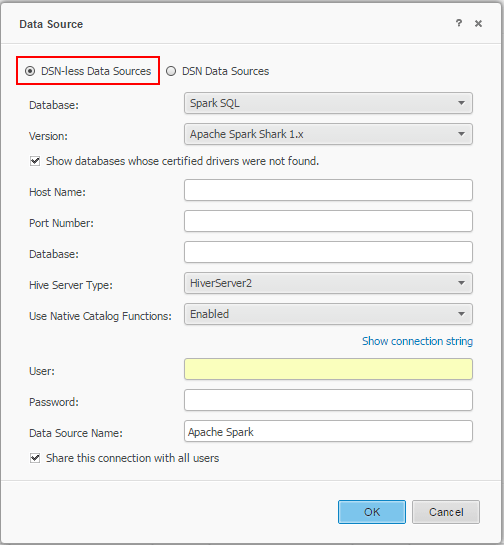
Note: Users can save the Data Import cube as a Live Connection or an In-Memory dataset.