SYMPTOM
Metadata partitioning in Strategy SQL Generation Engine identifies partitions by a filter defining a data slice. The data slices are compared against report filter qualifications to determine which partitions to use for metric calculation.
Refer to the article below for explaination of Metadata partitioning:
KB6540: Metadata partitioning in MicroStrategy SQL Generation Engine explained
Normally, when Strategy SQL Generation Engine issues SQL for tables partitioned within Strategy (for metadata or warehouse partitioning), metric calculation passes show a placeholder {|Partition_Base_Table|}. This placeholder is replaced at runtime, depending on the results of the partition pre-queries which identify the partitions to use.
Ex. 1
select a11.MONTH_ID MONTH_ID,
a13.CATEGORY_ID CATEGORY_ID,
sum(a11.EOH_QTY) WJXBFS1
into #ZZPO00
from {|Partition_Base_Table|} a11
join LU_ITEM a12
on (a11.ITEM_ID = a12.ITEM_ID)
join LU_SUBCATEG a13
on (a12.SUBCAT_ID = a13.SUBCAT_ID)
group by a11.MONTH_ID,
a13.CATEGORY_ID
For some metadata partition mapping tables, a separate pass of SQL may be generated for each base table, replacing {|Partition_Base_Table|} with the partition names in turn.
This example uses a simple schema in which two tables, Fact_Current and Fact_Historical, are linked by a metadata partition mapping table.
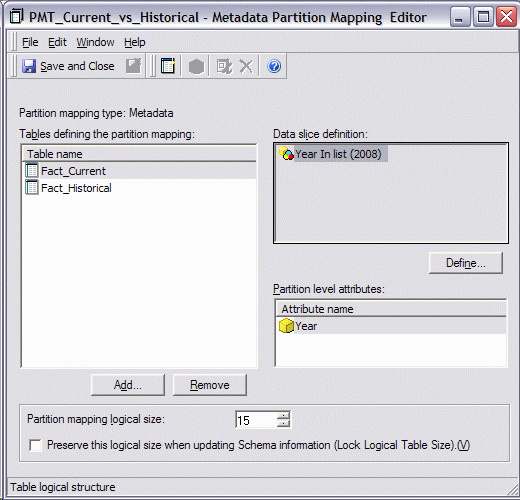
When SQL is viewed for a report containing the Year and Region attributes and a metric based on the partitioned tables, there are separate passes for both tables that appear to be redundant.
select count(*) AS WJXBFS1
from [LU_Year] a21
where (a21.[Year_ID] in (2007)
and a21.[Year_ID] in (2008))
select count(*) AS WJXBFS1
from [LU_Year] a21
where (a21.[Year_ID] in (2007)
and a21.[Year_ID] <= 2007)
[BEGIN PARTITION SQL, all 3 branches are showed and only one will be executed]
[1st BRANCH]
[Empty SQL]
[2nd BRANCH]
select distinct a12.[Year_ID] AS Year_ID,
a11.[Region_ID] AS Region_ID,
a13.[Region_DESC] AS Region_DESC,
a11.[Fact1] AS WJXBFS1
from [Fact_Current] a11,
[LU_Quarter] a12,
[LU_Region] a13
where a11.[Quarter_ID] = a12.[Quarter_ID] and
a11.[Region_ID] = a13.[Region_ID]
and a12.[Year_ID] in (2007)
select a11.[Year_ID] AS Year_ID,
a11.[Region_ID] AS Region_ID,
a12.[Region_DESC] AS Region_DESC,
a11.[Fact1] AS WJXBFS1
from [Fact_Historical] a11,
[LU_Region] a12
where a11.[Region_ID] = a12.[Region_ID]
and a11.[Year_ID] in (2007)
[3rd BRANCH]
create table ZZPO01 (
Region_ID LONG,
Year_ID LONG,
XKYCGT LONG,
WJXBFS1 DOUBLE)
insert into ZZPO01
select a11.[Region_ID] AS Region_ID,
a12.[Year_ID] AS Year_ID,
{|Extra_Column|} AS XKYCGT,
sum(a11.[Fact1]) AS WJXBFS1
from [Fact_Current] a11,
[LU_Quarter] a12
where a11.[Quarter_ID] = a12.[Quarter_ID]
and a12.[Year_ID] in (2007)
group by a11.[Region_ID],
a12.[Year_ID]
create table ZZPO01 (
Region_ID LONG,
Year_ID LONG,
XKYCGT LONG,
WJXBFS1 DOUBLE)
insert into ZZPO01
select a11.[Region_ID] AS Region_ID,
a11.[Year_ID] AS Year_ID,
{|Extra_Column|} AS XKYCGT,
a11.[Fact1] AS WJXBFS1
from [Fact_Historical] a11
where a11.[Year_ID] in (2007)
select pa11.[Year_ID] AS Year_ID,
pa11.[Region_ID] AS Region_ID,
max(a12.[Region_DESC]) AS Region_DESC,
sum(pa11.[WJXBFS1]) AS WJXBFS1
from [ZZPO01] pa11,
[LU_Region] a12
where pa11.[Region_ID] = a12.[Region_ID]
group by pa11.[Year_ID],
pa11.[Region_ID]
[END PARTITION SQL]
drop table ZZPO01
CAUSE
A metadata partition mapping is either homogeneous or heterogeneous. It is homogeneous if all the partitioned base tables have the same structure: same columns and data types, same attribute and fact mappings (which also implies that they will have the same key attributes). If there are any structural differences, the partition mapping will be heterogeneous.
To understand the impact on SQL generation, it is important to understand the workflow between the SQL Generation Engine and the Query Engine. In a report using application-level partitioning (Strategy metadata or warehouse partitioning), the SQL submitted to the database depends on the results of "pre-queries" that identify the partitions which are relevant to the report filter. Strategy does not pass the report back and forth between the engines, returning to the SQL Generation Engine after determining the partitions to use. Instead, the SQL Generation Engine must write every possible SQL statement that will be required. From these, the Query Engine chooses the appropriate statements depending on the pre-query results.
When a metadata partition mapping is homogeneous, the SQL Generation Engine can assume that all columns, FROM clause join paths and filtering conditions will be the same for every partition. Therefore, only one statement needs to be written with a placeholder for the actual partition name, as in example 1 above.
If the base table structures are different, the partitions may have different FROM clauses, which can also affect the table aliases in column references. The SQL Generation Engine produces a separate statement for each base table, and they are all displayed in the SQL view prior to executing the report. However, partitioning logic still applies; statements are submitted only if the pre-queries identify the associated table as matching the report filter.
This behavior for homogeneous partition mappings is required because the Query Engine, on its own, cannot generate different FROM clauses for base tables with different keys. The SQL Generation Engine must produce all the potentially-required statements before sending the job to the Query Engine. When SQL is viewed without executing the report, the display is this SQL Generation Engine result. After executing the report, the SQL has been processed by the Query Engine. Only the passes that were executed against the database are displayed.
ACTION
As the behavior is by design, no further action is needed.
To verify which passes are submitted to the warehouse, the report must be executed before viewing SQL.