SYMPTOM
An Intelligent Cube report is created in Strategy 9.0.1 or later, with the following characteristics:
A view report executed against this Intelligent Cube returns different results from a standard report with the same template that runs as SQL on the database. The view report's metric values are smaller, indicating that some fact rows from the database are not considered.
| |
CAUSE
This issue occurs because of an interaction between data characteristics, database configuration and Strategy Analytical Engine processing.
The key element in this issue is that there is a conflict between the case-sensitive data stored in the affected attribute's ID column and the case-insensitive collation used by the database. This can be observed by executing SQL directly against the warehouse:
| |
SELECT DISTINCT and GROUP BY operations fold 'abc' and 'Abc' into a single row because the case-insensitive collation specifies that case differences between any two strings should be ignored. By itself, this creates a data integrity problem. Which should be returned, 'abc' or 'Abc'? There is no way to specify in SQL; therefore queries that must group case-sensitive data in a case-insensitive collation are inherently ambiguous.
The SQL report shown above returns higher metric values because the database aggregates the fact values for 'abc' and 'Abc' together.
The Intelligent Cube that serves as the source for the example view report is configured to normalize incoming attribute data in the database using the option "Normalize Intelligent Cube data basing on dimensions with NO attribute lookup filtering." For each separate hierarchy on the template, a SELECT DISTINCT statement is issued against the attribute's primary lookup table to obtain a complete set of elements (without considering the Intelligent Cube report's filter). For the Capital attribute, the SELECT DISTINCT returns the two elements shown above: 'abc' and 'Bac'.
The Intelligent Cube report contains additional attributes that differentiate the four Capital elements found in the table. The metric result table, abbreviated for clarity, is as follows. Note that the database cannot group 'abc' and 'Abc' together because other selected attribute columns (which must also be considered in GROUP BY) have distinct values.

In Strategy OLAP Services, all string comparisons are case-sensitive. Thus, when the Analytical Engine matches the normalized metric table to the normalized Capital element list, the 'abc' and 'Bac' rows are preserved in the query and the others are dropped. That is, in the database, 'abc' = 'Abc' is true, but in the Analytical Engine, the same comparison is false.
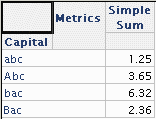
Thus the report based on the Intelligent Cube shows a value of 1.25 for 'abc', while the database aggregation returns 1.25 + 3.65 = 4.90 for the same element.
ACTION
The root cause of the issue is the use of a database collation (case-insensitive) that is inappropriate for the case-sensitive data. The discrepancy in the database configuration introduces ambiguity into SQL behavior, and ambiguity should generally be avoided in analytical applications. The ideal solution, then, is to change the database collation to handle the data unambiguously.
Further, data modeling best practices call for numeric attribute ID columns. The use of text columns for attribute IDs can impair query performance in the database and, in this scenario, opens the door to inconsistent data handling.
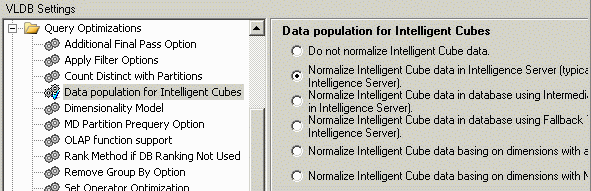
If it is not possible to improve data consistency in the database, the Intelligent Cube report may be configured to normalize data in the Intelligence Server. Either of the following options may be chosen for the "Data population for Intelligent Cube" VLDB property.
In either case, the Intelligence Server is responsible for determining the lists of distinct attribute elements, and this operation is always case sensitive. This will eliminate the discrepancy between the metric table and normalized attribute element tables that exist in the Intelligent Cube's in-memory data image.
After modifying the Intelligent Cube report to normalize data in Intelligence Server (second option), report executed against the cube no longer omit data that exist in the database. However, attribute elements that differ only in case will be differentiated.
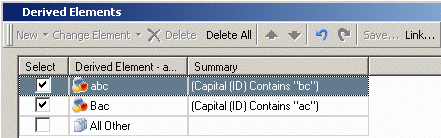
Derived elements may then be used to mimic the SQL results.

For more details on the behavior of the "Data Population for Intelligent Cube" VLDB property, consult the following Strategy Knowledgebase document.
KB32010: What are the Data Population VLDB properties in Strategy Engine 9.x?