
A common issue faced by many organizations is the synchronization of data lake updates with Strategy cube refresh. The most common scenario is that the data pipeline to update the data lake is managed by an enterprise scheduler, oozie, streamer or other kind of data ingestion manager. These updates usually occur and are expected to complete within a certain time window, often several times a day or hour. To keep Strategy cubes as current as possible, the usual method is to create Strategy cube publishing subscriptions that are triggered by a time-based schedule. These subscriptions are configured to run shortly after the data lake update is complete.
The synchronization strategy described above is most effective in environments where relevant data lake updates occur less frequently (e.g. daily) and can reliably complete before the Strategy cube refresh occurs.
With the Big Data trend, the factors of Velocity, Volume and Big Data Platform Architecture have an impact on the synchronization strategy in the following ways:
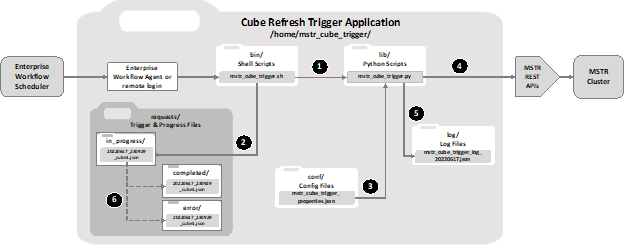
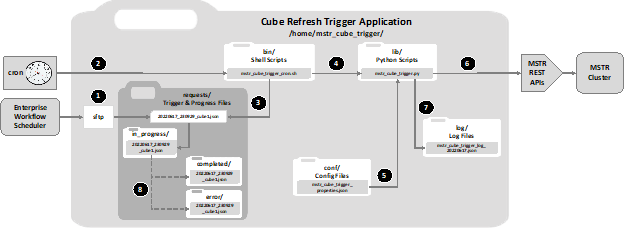
The solution discussed in this article is a python application that leverages the Strategy API suite to provide an external scheduler, i.e. the scheduler that manages the data lake updates, the ability to initiate an on-demand cube refresh immediately after the data lake update is complete. The application is named Strategy Cube Trigger, abbreviated as “MCT”.
MCT can be used asynchronously where the external scheduler initiates cube refresh but does not receive or interpret any status result, or it can be used synchronously in either a blocking or non-blocking mode where status results can be returned to the external scheduler.
When used synchronously in the non-blocking mode, MCT first checks whether the cube is available to be published and if so, initiates publishing, otherwise it does not attempt to publish and exits. A status result is returned to the external scheduler.
When used synchronously in the blocking mode, MCT first checks whether the cube is available and waits a specified duration for it to become available. If the cube becomes available within the waiting time window, publishing is initiated. A further option is available that causes MCT to wait until publishing is complete before exiting. A status result is returned to the external scheduler.
The following pseudo-code shows the application flow:
# Pseudo Code for MSTR Cube Trigger
mstr_cube_trigger(optional_request_list)
# Read config from properties file
get_properties(properties_file)
# Get request list from command line if not passed to function
if not optional_request_list:
get_json_request_from_argv()
# Login to Strategy
rest_api_login()
# Process request list
for request in request_list:
if update_type = "event":
# Re-publish by event-triggered subscription
trigger_event(request::event_spec)
if update_type = "api publish":
# Republish by cube api, irr api or subscription
if not skip_if_busy():
# Block until cube is available
wait_for_cube_ready(request::cube_spec)
if cube_ready():
# Publish by API
publish(request::cube_spec)
if synchronous = True:
# Block until the cube finishes publishing
wait_for_cube_ready(request::cube_spec)
rest_api_logout()
exit
Here are some examples of use case scenarios for the MCT:
Use Case | Trigger API | Cube Type | Method | Mode | Wait for Cube Ready | Skip Publish If Cube Not Ready | Wait for Publish To Complete | Outcome |
U01 | Event | MTDI | Event Driven Subscription | Async | n/a | n/a | n/a | Trigger cube refresh |
U02 | Event | OLAP | Event Driven Subscription | Async | n/a | n/a | n/a | Trigger cube refresh |
U03 | Event | OLAP | Event Driven IRR Subscription | Async | n/a | n/a | n/a | Trigger cube refresh |
U04 | Cube | MTDI | API | Async | N | Y | N | Execute refresh if cube ready else skip. Continue without wait. |
U05 | Cube | OLAP | API | Async | N | Y | N | Execute refresh if cube ready else skip. Continue without wait. |
U06 | IRR | OLAP | IRR API | Async | N | Y | N | Skip if cube is not ready. |
U07 | Subscr | MTDI | Immediate Subscription | Async | n/a | n/a | n/a | Directly execute cube refresh subscription. |
U08 | Cube | MTDI | API | Sync | Y | N | Y | Wait for cube ready before publish. Wait for cube to finish. |
U09 | Cube | OLAP | API | Sync | Y | N | Y | Wait for cube ready before publish. Wait for cube to finish. |
U10 | IRR | OLAP | IRR API | Sync | Y | N | Y | Wait for cube ready before publish. Wait for cube to finish. |
File Name: <path>/mstr_cube_trigger/bin/cube_trigger.sh
Usage: cube_trigger.sh <json_trigger_request_string>
Command | Result |
cube_trigger.sh ' {"mstr_cube_trigger":[ { "event":{"name":"RefreshCubeDemo"} } ]}' | trigger event by supplying event name |
cube_trigger.sh ' {"mstr_cube_trigger":[ { "event":{"id": "EB11845F9BEA70D22019AC39B4195BBD"} } ]}' | trigger event by supplying event id |
cube_trigger.sh ' {"mstr_cube_trigger":[ { "project":{ "id":"B016BFB5D096F11FDF107BAA42E836A1"}, "cube":{ "id":"B09B090080EFA512A8FE1FAD1D11EC4C", "skip if busy":"Y", "block until published":"N", "max block minutes":60 } } ]}' | publish cube by supplying project and cube id |
cube_trigger.sh ' {"mstr_cube_trigger": [ { "project":{"name":"Network Big Data"}, "folder":{"name":"Finance/Public Objects/Reports/Sales"}, "cube":{ "name":"MTDI Test Cube", "skip if busy":"Y", "block until published":"N", "max block minutes":60 } } ]}' | publish cube by supplying project, folder and cube names |
cube_trigger.sh ' {"mstr_cube_trigger":[ { "project":{"id":"B016BFB5D096F11FDF107BAA42E836A1"}, "folder":{"id":"1A725C3268C2D25D608FDFF087F4AD28"}, "cube":{"name": "MTDI Test Cube"} } ]}' | publish cube by supplying project, folder and cube id and name mix |
Another article will be published shortly to show code examples and how install the application.