Starting with the release of Strategy ONE (March 2024), dossiers are also known as dashboards.
In my first example "Data Lineage: direct and extended object relations (two levels) " I have created a script that gathers all direct and extended relations between. The result was a visualization that allowed to see one level deep relations.
In this example I am collecting data that allow building a deeper hierarchy. It is the most common hierarchy while analyzing Strategy objects lineage:
Document > Dataset > Report Object > Schema Object > Table
This approach may give a better overview of the complexity of a Project. If you compare it to the first approach it may give you additional information about metrics that are never used anywhere or reports that exist only as a standalone reports and are never used as datasets to documents or dossiers. It also helps with finding dossiers datasets that are imported Excel files. On the other hand there are some limitations as well. With this approach not every relation was captured, for example prompts, custom groups and some other objects were not included into the analysis. This would require further development of the script.
Putting all the hierarchy levels on Sankey diagram helps understanding project complexity.
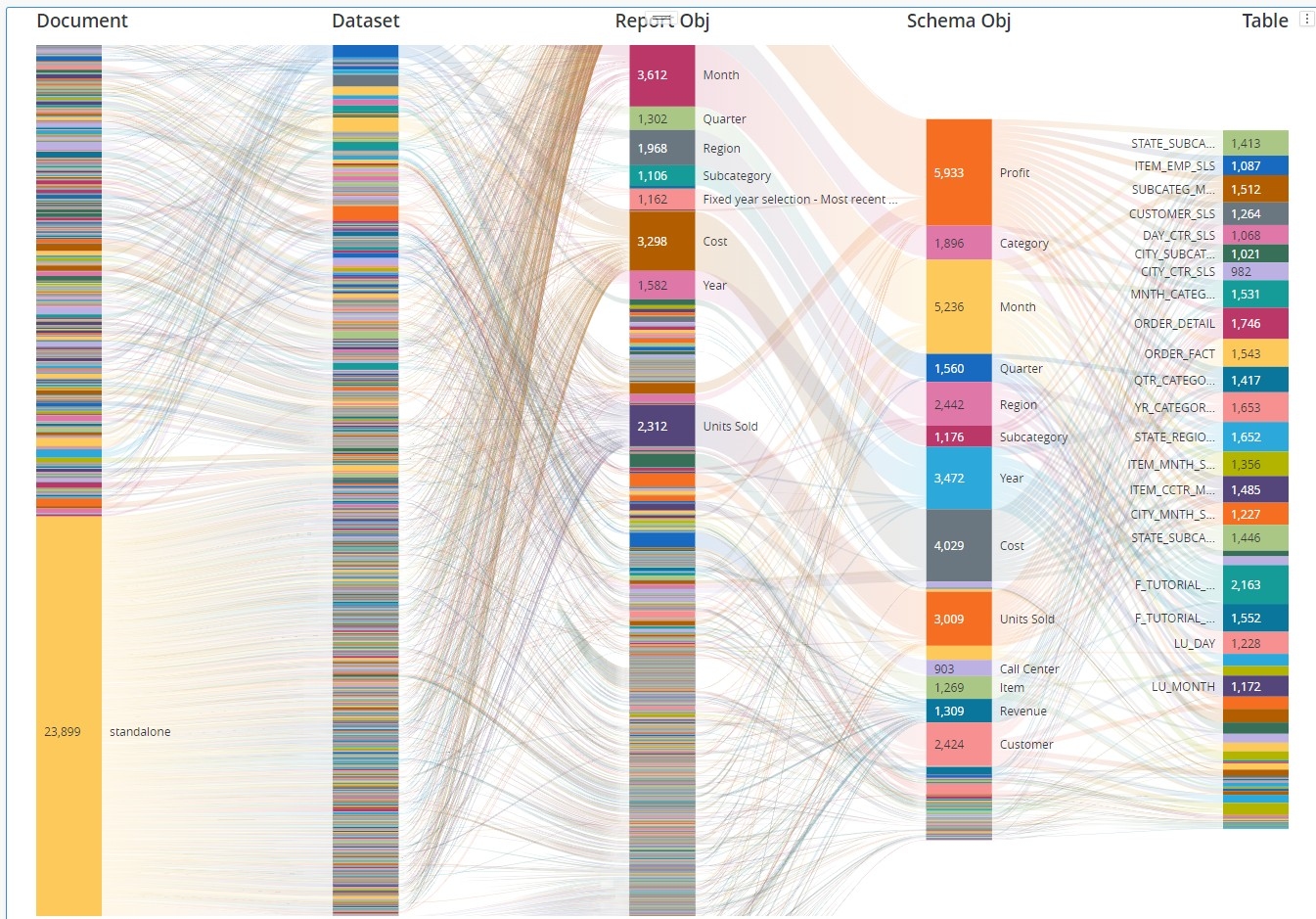
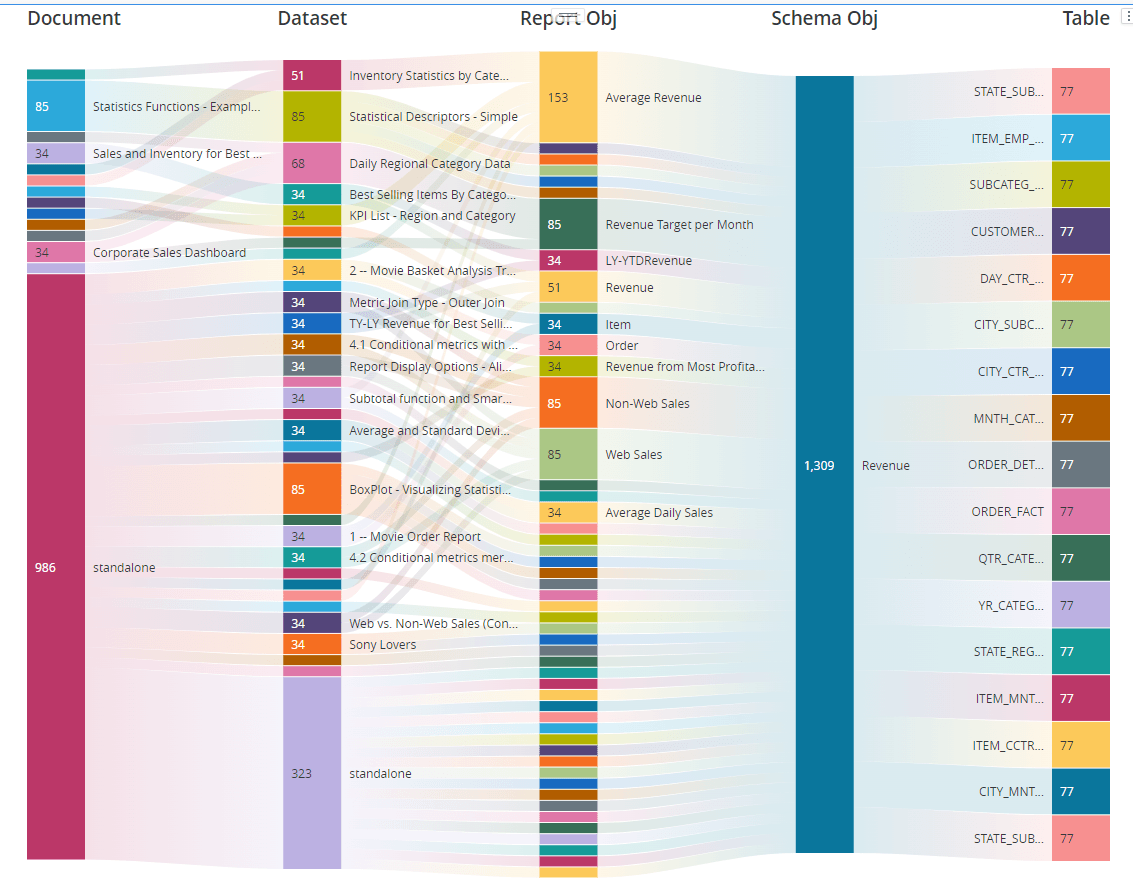
It may get a clearer view to add a filter for example on Revenue fact (schema object).
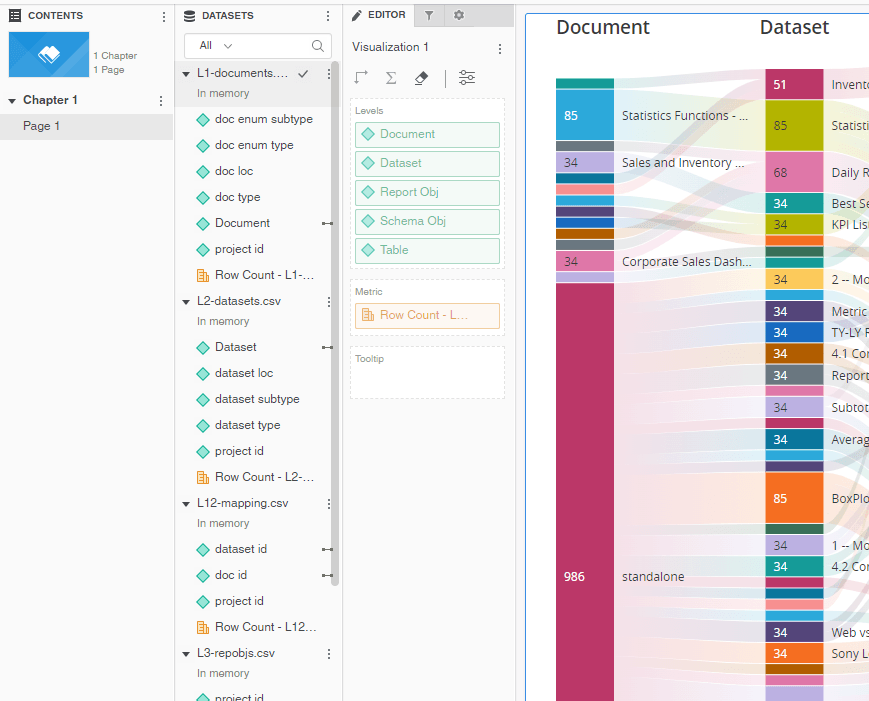
In order to make the Sankey diagram I would not recommend creating one MTDI cube with 8 internal tables. You will get a better performance by importing the CSV files separately into the dossier and only then link common attributes between tables. You will notice there are main lookup tables (like L1-documents.csv or L2-datasets.csv) and mapping tables that contain relations (L12-mapping.csv). You may want to use attached dossier in mstr format to see which attributes were linked and how.
I am attaching example CSV files that the script produces while runing it against Tutorial Project. I am also attaching the Python code both as .py and .ipynb (Jupyter Lab) formats. This example is based on Strategy 2021 u.10 and mstrio library 11.3.10.101.
Please note - I've added color formatting in the code below (http://hilite.me/). Code copied from here might not work due to indentation issues. In that case, use attached file with sample code. Also this CRM is adding ';' after URLs.
#!/usr/bin/env python
# coding: utf-8
# --- HIERARCHY ---
#
# 0. Project
# 1. Document (dossier, document)
# - mapping 1 and 2
# 2. Dataset (report, OLAP cube, data import, internal dossier dataset)
# - mapping 2 and 3
# 3. Report Object (attribute, metric)
# - mapping 3 and 4
# 4. Schema Object (attribute, fact)
# 5. Table
# 6. Datasource
#
# In[ ]:
import csv, json, pickle, itertools
import pandas as pd
import getpass
from mstrio.connection import Connection
from mstrio.server import Environment, Project
from mstrio.object_management import full_search
from mstrio.types import ObjectSubTypes, ObjectTypes
from mstrio.project_objects.datasets.super_cube import SuperCube
from mstrio import config
config.verbose = False
# In[ ]:
mstr_username = "mstr"
mstr_password = getpass.getpass(prompt='Password ')
mstr_base_url = "https://env-319699.customer.cloud.Strategy.com"
mstr_url_api = mstr_base_url+"/StrategyLibrary/api"
# upload to cube
upload_proj_id = "B7CA92F04B9FAE8D941C3E9B7E0CD754"
upload_folder_id = "C113BFA19445341FDC72358312FAD611"
# Output format
cube_export = False # make it False if you don't need push data to cubes
csv_export = True # ..
KEY_SF = "standalone" #keyword for objects without parent like a metric that is never used in any report
pickle_file = "cube_dict3.pkl"
# In[ ]:
# Connection
conn=Connection(mstr_url_api, mstr_username, mstr_password, login_mode=1)
env = Environment(connection=conn)
# # Functions
# In[ ]:
def export_to_csv(level_id, df):
df.to_csv(f"{level_id}.csv", index=False, encoding='utf-8', sep=",", quoting=csv.QUOTE_ALL, escapechar="\\", header=True)
def create_new_cube(mstr_connection, folder_id, level_id, df, header, update_policy):
dataset = SuperCube(mstr_connection, name=level_id)
dataset.add_table(name=level_id, data_frame=df, update_policy=update_policy, to_attribute=header, to_metric=[])
dataset.create(folder_id=folder_id)
return dataset.id
def push_to_cube(mstr_connection, cube_id, level_id, df, update_policy):
dataset = SuperCube(mstr_connection, id=cube_id)
dataset.add_table(name=level_id, data_frame=df, update_policy=update_policy)
dataset.update()
def push_data(conn, cube_export, csv_export, level_id, datalist, update_policy):
df = pd.DataFrame(datalist, columns = cubes_ids[level_id][1])
if csv_export:
export_to_csv(level_id, df)
if cube_export:
conn.select_project(project_id=upload_proj_id)
push_to_cube(conn, cubes_ids[level_id][0], level_id, df, update_policy)
def unique_list(alist): # sorts a list of lists
alist.sort()
alist=list(alist for alist,_ in itertools.groupby(alist))
return alist
def get_dependants(mstr_obj, project_id, parent_id): # this will work for Reports, Metrics, (?)
return [[project_id, parent_id, d["type"], d["id"], d["name"]] for d in mstr_obj.list_dependencies()]
def get_object_deps(r, project_id): # this one takes an object to search
deps=r.list_dependencies()
return [[project_id, r.type.value, r.id, r.name, d["type"], d["id"], d["name"]] for d in deps]
def search_deps(conn, project_id, obj_id, obj_type): # this one takes an object ID to search
objects = full_search(
conn,
project=project_id,
used_by_object_id=obj_id,
used_by_object_type=obj_type
)
return [[d["type"],d["id"],d["name"]] for d in objects]
def resolve_down(conn, pid, object_dependants, deps_to_resolve, deps_finished):
while deps_to_resolve:
for dtr in deps_to_resolve[:]:
pid,rep_type,rep_id,rep_name = dtr[0],dtr[1],dtr[2],dtr[3] #those params will be used for recursive search
dep_type,dep_id,dep_name = dtr[4],dtr[5],dtr[6]
print("\n### Dependency name:",dep_name,dep_id,dep_type)
# we can eliminate dependencies we already know and deps of weird objects like functions
if (dep_id in [o[2] for o in object_dependants]) or (dep_type in [11,61,53,22,26]):
print("Already checked or unnecessary")
else:
deps=search_deps(conn, pid, dep_id, dep_type)
if deps: # there are objects like functions without components
print("# of components:",len(deps))
for nd in deps:
dep_nd=[pid,dep_type,dep_id,dep_name,nd[0],nd[1],nd[2]]
rep_nd=[pid,rep_type,rep_id,rep_name,nd[0],nd[1],nd[2]]
# ADD deps to object_dependants : dep + nd
object_dependants.append(dep_nd)
print(dep_nd, "added to object_dependants")
if nd[0] in [4,7,12,13]:
# ADD deps to deps_finished : rep + nd
deps_finished.append(rep_nd)
print(rep_nd, "added to deps_finished")
else:
# ADD deps to deps_to_resolve : rep + nd
deps_to_resolve.append(rep_nd)
print(rep_nd, "added to deps_to_resolve")
else:
object_dependants.append([pid,dep_type,dep_id,dep_name,0,"NA","NA"])
print("empty component added to object_dependants")
deps_to_resolve.remove(dtr)
print(f"Number of objects that remain to be resolved: {len(deps_to_resolve)}")
print("Objects terminal dependecies to SO identified:",len(deps_finished))
print("Objects to be resolved:",len(deps_to_resolve))
return deps_finished
def get_dossier_definition(connection, dossier_id):
url_add=f"/api/v2/dossiers/{dossier_id}/definition"
res = connection.get(url=connection.base_url+url_add)
return res
def map_standalone_obj(map_list, child_obj_list, child_obj_position):
map_list_std = unique_list([[m[0],m[2]] for m in map_list])
child_obj_list_std = unique_list([[m[0],m[child_obj_position]] for m in child_obj_list])
for d in child_obj_list_std:
if d not in map_list_std:
map_list.append([d[0],KEY_SF,d[1]])
return map_list
# # Preparation
# ### Create Cubes if you plan to upload data there
# #### You may want to do CSV export only. Currently (August 2023) mstrio does not allow creating multiform attributes - which makes it difficult to create a Sankey Diagram for this use case. It works, though, with importing csv file via data import wizard.
# In[ ]:
cubes_ids={} # this will store all cubes IDs
cube_dtl={
"L0-projects": [["project_id", "project_name"], [["x","x"]]],
"L1-documents": [["project_id","doc_type","doc_id","doc_name","doc_enum_type","doc_enum_subtype","doc_loc"],
[["x","x","x","x",0,0,"x"]]],
"L2-datasets": [["project_id","dataset_type","dataset_subtype","dataset_id","dataset_name","dataset_loc"],
[["x","x",0,"x","x","x"]]],
"L3-repobjs": [["project_id","repobj_type","repobj_subtype","repobj_id","repobj_name"],
[["x","x",0,"x","x"]]],
"L4-schemaobjs": [["project_id","tbl_name", "tbl_id" , "tbl_data_source", "schemaobj_type",
"schemaobj_id", "schemaobj_name", "attr_lu_table", "form_name",
"form_datatype", "form_precision", "expression"],
[["x","x","x",0,"x","x","x","x","x","x","x","x"]]],
"L12-mapping": [["project_id","doc_id","dataset_id"], [["x","x","x"]]],
"L23-mapping": [["project_id","dataset_id","repobj_id"], [["x","x","x"]]],
"L34-mapping": [["project_id","repobj_id","schemaobj_id"], [["x","x","x"]]]
}
for cube in cube_dtl.keys():
headers, datasample=cube_dtl[cube]
df = pd.DataFrame(datasample, columns = headers)
conn.select_project(project_id=upload_proj_id)
cube_id=create_new_cube(conn, upload_folder_id, cube, df, headers, "replace")
print(cube, cube_id)
cubes_ids[cube]=[cube_id,headers]
# In[ ]:
# Save cube ids into a pickle file
f = open(pickle_file,"wb") # save cube ID to file
pickle.dump(cubes_ids,f)
f.close()
# # Start collecting data
# ### Load cube ids
# In[ ]:
f = open(pickle_file,"rb") # read saved user counts
cubes_ids = pickle.load(f)
print(cubes_ids)
f.close()
# # 0. Projects
# In[ ]:
loaded_projects = env.list_loaded_projects()
print("Loaded projects: ",len(loaded_projects))
for p in loaded_projects:
print(p.id, p.name)
# In[ ]:
# limit the list of projects
selected_projects=loaded_projects[:1]
selected_projects=[[p.id, p.name] for p in selected_projects]
print(selected_projects)
# #### Export/Upload
# In[ ]:
push_data(conn, cube_export, csv_export, "L0-projects", selected_projects, "replace")
# # 1. Document (dossier, document)
# In[ ]:
from mstrio.project_objects.dossier import list_dossiers
from mstrio.project_objects.document import list_documents
documents_all = []
for project in selected_projects:
pid=project[0]
conn.select_project(project_id=pid)
documents_all.append([pid, KEY_SF, KEY_SF, KEY_SF, 0, 0])
dossiers_list = list_dossiers(connection=conn, project_id=pid)
print(f"\nNumber of dossiers found: {len(dossiers_list)}")
documents_list = list_documents(connection=conn, project_id=pid)
print(f"Number of documents found: {len(documents_list)}")
for i, d in enumerate(dossiers_list[:]):
documents_all.append([pid, "DOSSIER",d.id,d.name,d.type.name,d.subtype,d.ancestors[1]['name']])
print("Dossiers finished...")
for i, d in enumerate(documents_list[:]):
documents_all.append([pid, "DOCUMENT",d.id,d.name,d.type.name,d.subtype,d.ancestors[1]['name']])
print("Documents finished...")
print("All Document objects:",len(documents_all))
# #### Export/Upload
# In[ ]:
push_data(conn, cube_export, csv_export, "L1-documents", documents_all, "replace")
# # 2. Dataset (report, OLAP cube, data import, internal dossier dataset)
# ## Contains 1-2 Mapping AND 2-3 Mapping (first part)
# There will be 4 types of datasets:
# - regular reports
# - OLAP cubes
# - dossier datasets: data import dataset
# - dossier datasets: datasets built from objects within dossiers
# In[ ]:
# this one will do reports and OLAP cubes
from mstrio.project_objects.report import list_reports
datasets_all = []
for project in selected_projects:
pid=project[0]
conn.select_project(project_id=pid)
datasets_all.append([pid, KEY_SF, 0, KEY_SF, KEY_SF, ''])
reports_list = list_reports(connection=conn, project_id=pid)
print(f"\nNumber of reports found: {len(reports_list)}")
for i, r in enumerate(reports_list[:]):
datasets_all.append([pid, r.type.name.upper(), r.subtype, r.id, r.name, r.ancestors[1]['name']])
print("All Dataset objects in current Project:",len(datasets_all))
print("\n\nAll Dataset objects:",len(datasets_all),"\n")
# ### Import internal only dossier datasets
# In[ ]:
from mstrio.project_objects.dossier import list_dossiers
l12_mapping = [] # this will be mapping dossier/document with their datasets
l2_non_schema_datasets = [] # this will collect details of non schema dataset (internal dossier or data import)
l23_mapping = [] # this will be mapping non schema datasets with report objects
for project in selected_projects:
pid=project[0]
print(project[1])
conn.select_project(project_id=pid)
l12_mapping.append([pid, KEY_SF, KEY_SF])
l23_mapping.append([pid, KEY_SF, KEY_SF])
# existing "normal" schema datasets in current project
dataset_ids=[did[3] for did in datasets_all if did[0]==pid]
dossiers_list = list_dossiers(connection=conn)
for i, d in enumerate(dossiers_list[:]):
print(i+1,"/", len(dossiers_list), " - ", d.name, d.id, d.type.name)
r=get_dossier_definition(conn, d.id).json()
for dset in r['datasets']:
if dset['id'] not in dataset_ids:
l12_mapping.append([pid, d.id, dset['id']])
l2_non_schema_datasets.append([pid,"DATASET", 0, dset['id'], dset['name'], "dynamic"])
for ao in dset['availableObjects']:
l23_mapping.append([pid,dset['id'],ao['id']])
else:
l12_mapping.append([pid, d.id, dset['id']])
print(f"\nDossiers finished... Mappings Count: {len(l12_mapping)}")
documents_list = list_documents(connection=conn, project_id=pid)
print(f"\nNumber of documents found: {len(documents_list)}")
for i, d in enumerate(documents_list[:]):
print(i+1,"/", len(documents_list), " - ", d.name, d.id, d.type.name)
for c in get_object_deps(d, pid):
if c[4]==3: # found report object
l12_mapping.append([pid, d.id, c[5]])
print(f"\nDocuments finished... Mappings Count: {len(l12_mapping)}")
# In[ ]:
l12_mapping=unique_list(l12_mapping)
l23_mapping=unique_list(l23_mapping)
l2_non_schema_datasets=unique_list(l2_non_schema_datasets)
datasets_all+=l2_non_schema_datasets
# #### Make sure standalone reports are added to mapping table
# In[ ]:
l12_mapping = map_standalone_obj(l12_mapping, datasets_all, 3)
# In[ ]:
'''
l12_map_std = unique_list([[m[0],m[2]] for m in l12_mapping])
datasets_all_std = unique_list([[m[0],m[3]] for m in datasets_all])
print(len(l12_map_std), " / ", len(datasets_all_std))
l12_mapping_new=[]
for d in datasets_all_std:
if d not in l12_map_std:
l12_mapping_new.append([d[0],KEY_SF,d[1]])
l12_mapping.extend(l12_mapping_new)
'''
# #### Export/Upload
# In[ ]:
push_data(conn, cube_export, csv_export, "L2-datasets", datasets_all, "replace")
push_data(conn, cube_export, csv_export, "L12-mapping", l12_mapping, "replace")
push_data(conn, cube_export, csv_export, "L23-mapping", l23_mapping, "replace") # remember to do 'add' in L23 mapping below
# # 3. Report Objects (Attributes, Metrics, Facts)
# In[ ]:
len(l23_mapping)
# In[ ]:
from mstrio.modeling.schema import list_attributes, list_facts
from mstrio.modeling import list_metrics, list_filters
report_obj_all = []
for project in selected_projects:
pid=project[0]
print(project[1])
conn.select_project(project_id=pid)
report_obj_all.append([pid, KEY_SF, 0, KEY_SF, KEY_SF])
list_of_all_atrs = list_attributes(connection=conn, project_id=pid)
print(f"Number of attributes found: {len(list_of_all_atrs)}")
list_of_all_metr = list_metrics(connection=conn, project_id=pid)
print(f"Number of metrics found: {len(list_of_all_metr)}")
list_of_all_fact = list_facts(connection=conn, project_id=pid)
print(f"Number of facts found: {len(list_of_all_fact)}")
list_of_all_filtr = list_filters(connection=conn, project_id=pid)
print(f"Number of filters found: {len(list_of_all_filtr)}")
for i, r in enumerate(list_of_all_atrs[:]):
report_obj_all.append([pid, r.type.name.upper(), r.subtype, r.id, r.name])
for i, r in enumerate(list_of_all_metr[:]):
report_obj_all.append([pid, r.type.name.upper(), r.subtype, r.id, r.name])
for i, r in enumerate(list_of_all_fact[:]):
report_obj_all.append([pid, r.type.name.upper(), r.subtype, r.id, r.name])
for i, r in enumerate(list_of_all_filtr[:]):
report_obj_all.append([pid, r.type.name.upper(), r.subtype, r.id, r.name])
print("All report objects:",len(report_obj_all),"\n")
# #### Export/Upload
# In[ ]:
push_data(conn, cube_export, csv_export, "L3-repobjs", report_obj_all, "replace")
# # 23 Mapping
# In[ ]:
from mstrio.project_objects.report import list_reports
from mstrio.object_management import full_search
from mstrio.types import ObjectSubTypes, ObjectTypes
# initially, this will contain dependatns of reports
# later, I will add any new object found for reference, to avoid double checking
object_dependants = []
deps_completed_all=[]
for project in selected_projects:
pid=project[0]
print(pid, project[1])
conn.select_project(project_id=pid)
reports_list = list_reports(connection=conn, project_id=pid)
print(f"\nNumber of reports found: {len(reports_list)}\nGetting components of each report now")
for i, r in enumerate(reports_list[:]):
print(f"{i}/{len(reports_list)} --- {r.name} --- {r.id}")
object_dependants.extend(get_object_deps(r, pid))
print("All report objects components:",len(object_dependants),"\n\n")
# Let's split what is already done from objects to resolse
deps_finished=[] # already identified dependencies down to Report Objects
deps_to_resolve=[] # dynamic list of objects to resolve (check deps)
for d in object_dependants:
if d[4] in [4,7,12,13,1]:
deps_finished.append(d)
else:
deps_to_resolve.append(d)
print("Reports RO dependecies identified:",len(deps_finished))
print("Objects to be resolved:",len(deps_to_resolve))
print("\nResolving dependencies of remaining objects now")
deps_finished=resolve_down(conn, pid, object_dependants, deps_to_resolve, deps_finished)
deps_completed_all.extend(deps_finished)
print("Job finished for Project:",pid, project[1],"\n\n")
# #### Find and flag standalone objects
# In[ ]:
map23=[[m[0],m[2],m[5]] for m in deps_completed_all]
map23.extend(l23_mapping) #add mappings from internal dossier datasets retrieved in the previous chapter
map23=unique_list(map23)
print(f"Mappings count before: {len(map23)}")
map23 = map_standalone_obj(map23, report_obj_all, 3)
map23=unique_list(map23)
print(f"Mappings count after: {len(map23)}")
# #### Export/Upload
# In[ ]:
push_data(conn, cube_export, csv_export, "L23-mapping", map23, "replace")
# # 4-6. attributes, facts, tables, data sources
# In[ ]:
### Check why subtype is empty
# In[ ]:
from mstrio.modeling.schema.table import list_logical_tables
conn.select_project(project_id=pid)
tables_list = list_logical_tables(connection=conn)
# In[ ]:
from mstrio.modeling.schema.table import list_logical_tables
for project in selected_projects:
pid=project[0]
print(project[1])
conn.select_project(project_id=pid)
tables_list = list_logical_tables(connection=conn)
data_list=[]
for i, table in enumerate(tables_list[:]):
print("\n", i," / ",len(tables_list)," >>> ===========")
print(table.name, table.id, table.subtype, table.primary_data_source.name)
print("===========")
if table.attributes and table.subtype==3840:
for a in table.attributes:
if a.id and a.sub_type=="attribute": # and a.subtype==3072
aa=a.list_properties() ## Important! it downloads all the details
print("\n-- ", a.name, a.id, a.subtype, a.sub_type)
for form in a.forms:
if not form.is_form_group: # eliminate grouped forms
form_name=form.name
print("### ", form_name, form.data_type)
try:
altn=a.attribute_lookup_table.name
except:
altn="No altn"
if form.data_type:
form_datatype,form_precis=form.data_type.type, form.data_type.precision
for expr in form.expressions:
expr_text = expr.expression.text
data_list.append([pid, table.name, table.id,table.primary_data_source.name,
a.type.name, a.id, a.name,
altn, form_name,form_datatype,
form_precis, expr.expression.text])
else:
form_datatype,form_precis,expr_text="NA","NA","NA"
data_list.append([pid, table.name, table.id,table.primary_data_source.name,
a.type.name, a.id, a.name,
altn, form_name,form_datatype,
form_precis, expr.expression.text])
if table.facts:
for f in table.facts:
if f.id:
print("\nFACTS")
for expr in f.expressions:
# facts do not have forms - add NA instead
data_list.append([pid, table.name, table.id, table.primary_data_source.name, f.type.name, f.id, f.name, "NA", "NA",f.data_type.type, f.data_type.precision, expr.expression.text])
# #### Export/Upload
# In[ ]:
push_data(conn, cube_export, csv_export, "L4-schemaobjs", data_list, "replace")
# # 3-4 Mapping
# In[ ]:
from mstrio.modeling import (list_metrics, Metric)
from mstrio.modeling.expression import Expression, Token
from mstrio.object_management import full_search
from mstrio.types import ObjectSubTypes, ObjectTypes
# initially, this will contain dependatns of reports
# later, I will add any new object found for reference, to avoid double checking
object_dependants = []
deps_completed_all=[]
for project in selected_projects:
pid=project[0]
print(pid, project[1])
conn.select_project(project_id=pid)
metrics_list = list_metrics(connection=conn, project_id=pid)
print(f"\nNumber of metrics found: {len(metrics_list)}\nGetting components of each metric now")
for i, r in enumerate(metrics_list[:]):
print(f"{i}/{len(metrics_list)} --- {r.name}")
object_dependants.extend(get_object_deps(r, pid))
filters_list = list_filters(connection=conn, project_id=pid)
print(f"\nNumber of filters found: {len(filters_list)}\nGetting components of each filter now")
for i, r in enumerate(filters_list[:]):
print(f"{i}/{len(filters_list)} --- {r.name}")
object_dependants.extend(get_object_deps(r, pid))
print("All report objects components:",len(object_dependants),"\n\n")
# Let's split what is already done from objects to resolse
deps_finished=[] # already identified dependencies down to Report Objects
deps_to_resolve=[] # dynamic list of objects to resolve (check deps)
for d in object_dependants:
if d[4] in [4,7,12,13]:
deps_finished.append(d)
else:
deps_to_resolve.append(d)
print("Metrics RO dependecies identified:",len(deps_finished))
print("Objects to be resolved:",len(deps_to_resolve))
print("\nResolving dependencies of remaining objects now")
deps_finished=resolve_down(conn, pid, object_dependants, deps_to_resolve, deps_finished)
deps_completed_all.extend(deps_finished)
print("Job finished for Project:",pid, project[1],"\n\n")
# #### Remove subtotals
# In[ ]:
subtotals=["00B7BFFF967F42C4B71A4B53D90FB095",
"078C50834B484EE29948FA9DD5300ADF",
"1769DBFCCF2D4392938E40418C6E065E",
"36226A4048A546139BE0AF5F24737BA8",
"54E7BFD129514717A92BC44CF1FE5A32",
"7FBA414995194BBAB2CF1BB599209824",
"83A663067F7E43B2ABF67FD38ECDC7FE",
"96C487AF4D12472A910C1ACACFB56EFB",
"B1F4AA7DE683441BA559AA6453C5113E",
"B328C60462634223B2387D4ADABEEB53",
"E1853D5A36C74F59A9F8DEFB3F9527A1",
"F225147A4CA0BB97368A5689D9675E73"]
map34=[[m[0],m[2],m[5]] for m in deps_completed_all if m[5] not in subtotals]
map34=unique_list(map34)
# #### Add attr-to-attr and fact-to-fact mappings
# In[ ]:
from mstrio.modeling.schema import list_attributes
from mstrio.modeling.schema import list_facts
attrs_facts = []
for project in selected_projects:
pid=project[0]
print(project[1])
conn.select_project(project_id=pid)
#report_obj_all.append([pid, 'NA', 0, 'NA', 'NA'])
list_of_all_atrs = list_attributes(connection=conn, project_id=pid)
print(f"Number of attributes found: {len(list_of_all_atrs)}")
list_of_all_fact = list_facts(connection=conn, project_id=pid)
print(f"Number of facts found: {len(list_of_all_fact)}")
for i, r in enumerate(list_of_all_atrs[:]):
attrs_facts.append([pid,r.id, r.id])
for i, r in enumerate(list_of_all_fact[:]):
attrs_facts.append([pid, r.id, r.id])
print("All report objects:",len(attrs_facts))
map34.extend(attrs_facts)
# #### Find and flag standalone objects
# In[ ]:
print(f"Mappings count before: {len(map34)}")
map34 = map_standalone_obj(map34, attrs_facts, 1)
map34=unique_list(map34)
print(f"Mappings count after: {len(map34)}")
# #### Export/Upload
# In[ ]:
push_data(conn, cube_export, csv_export, "L34-mapping", map34, "replace")